Red Hat 为 Podman Desktop 提供了一个扩展,Podman AI Lab,它让开发人员可以通过使用大型语言模型 (LLM) 发现应用程序示例,并为他们提供一个框架来创建自己的基于 AI 的应用程序并与团队共享。
通过本文,我们将探索创建我们的第一个 AI 应用程序,并将其添加到 Podman AI Lab 的配方目录中的不同步骤。
对于我们的第一次实验,我们将为 podman-desktop.io 网站开发一个微服务。该微服务将接收来自网站的搜索词,并要求模型找到最匹配的页面,然后将结果返回给网站。

准备 Podman Desktop 和 Podman AI Lab
如果您还没有安装,请先安装 Podman Desktop 及其扩展 Podman AI Lab。
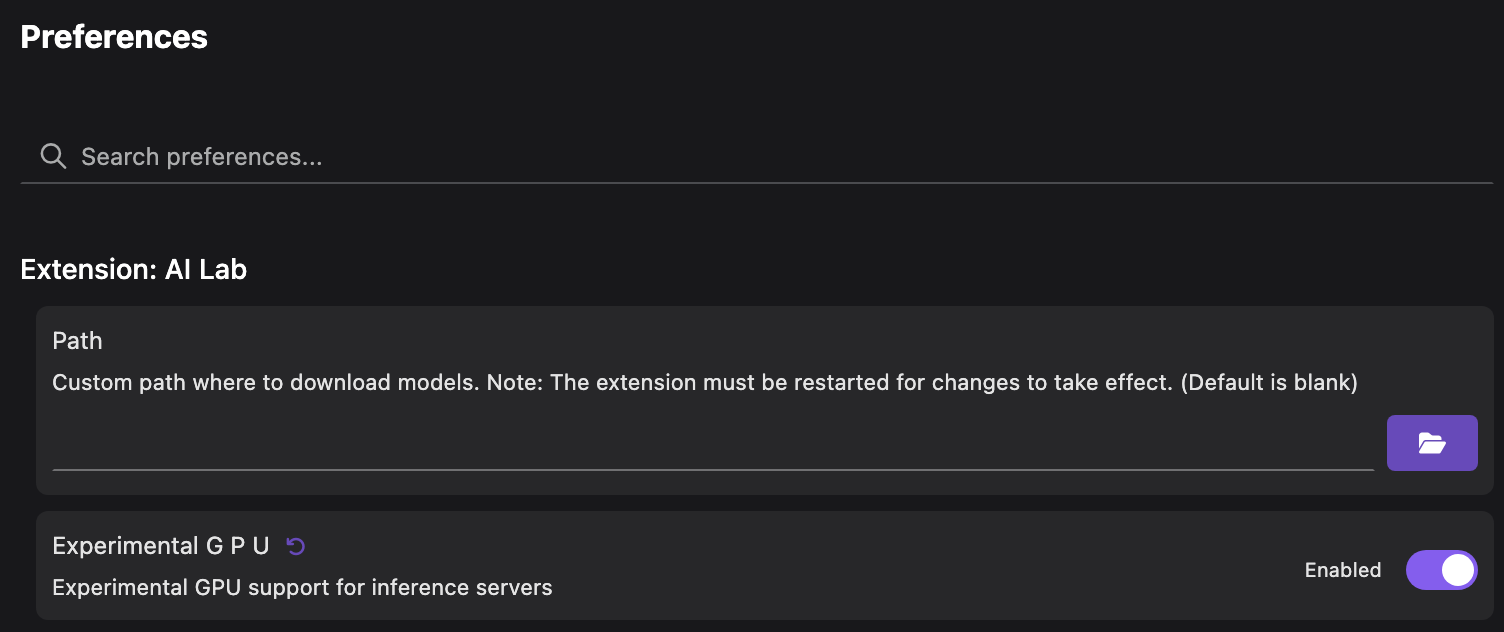
为了获得更好的体验,建议使用 GPU 加速来提供模型。如果您的机器上安装了此类 GPU,您需要使用 LibKrun 提供程序(在 MacOS 上)创建一个 Podman 机器。有关 Podman AI Lab 的 GPU 支持的更多详细信息。
在撰写本文时,Podman AI Lab 的 GPU 支持仍处于实验阶段。您需要在首选项中启用该选项才能使用。
使用模型测试提示
Podman AI Lab 提供了一个可本地使用的开源模型目录。您可以前往 `Models > Catalog` 页面下载您选择的模型。在本文中,我们将使用 `Mistral-7B-instruct` 模型。

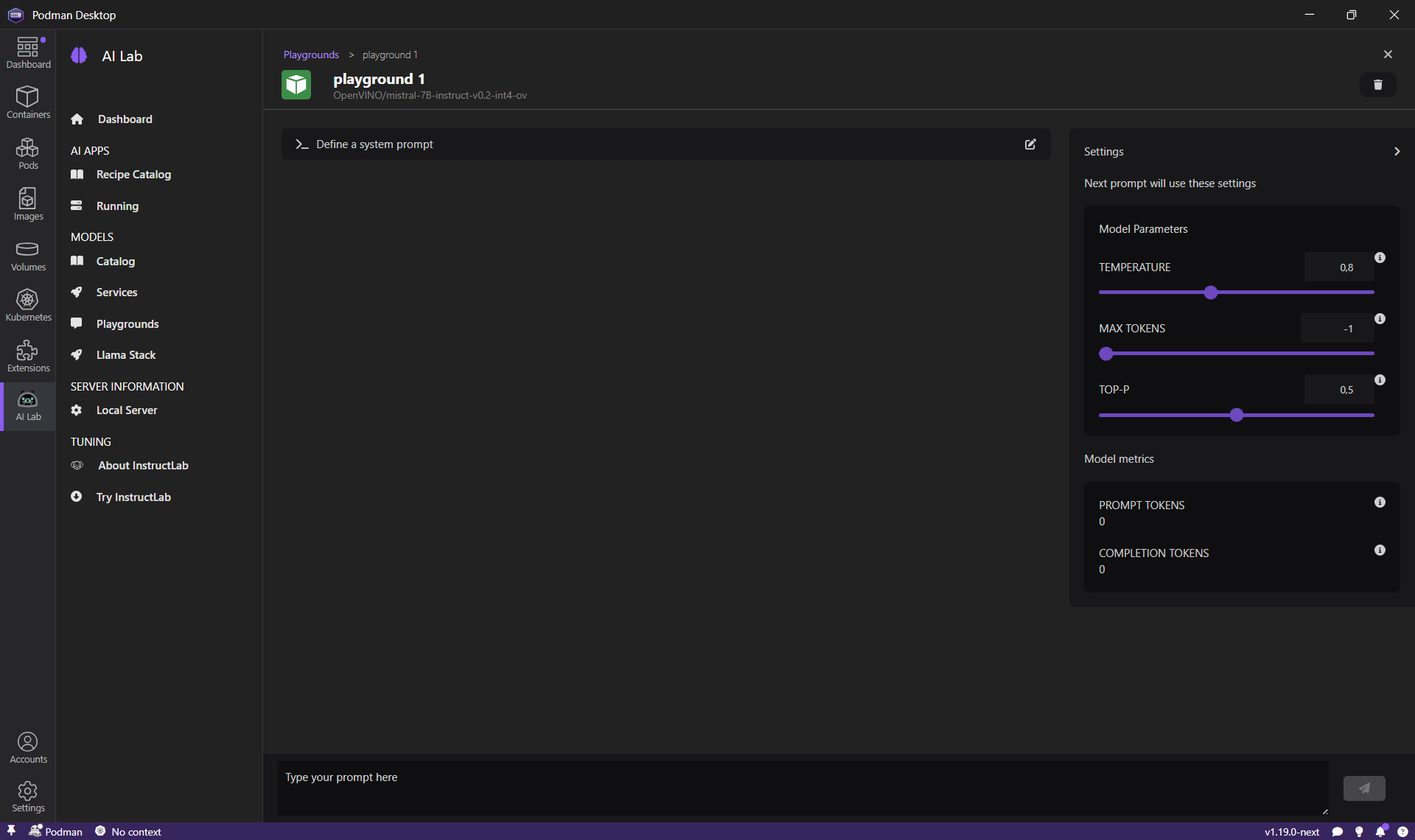
模型下载完成后,我们可以测试并与该模型交互,以尝试为我们的应用程序找到最佳提示。对于聊天模型,Podman AI Lab 提供了一个 `Playground`,因此我们可以测试不同的提示并验证模型的响应是否足够。
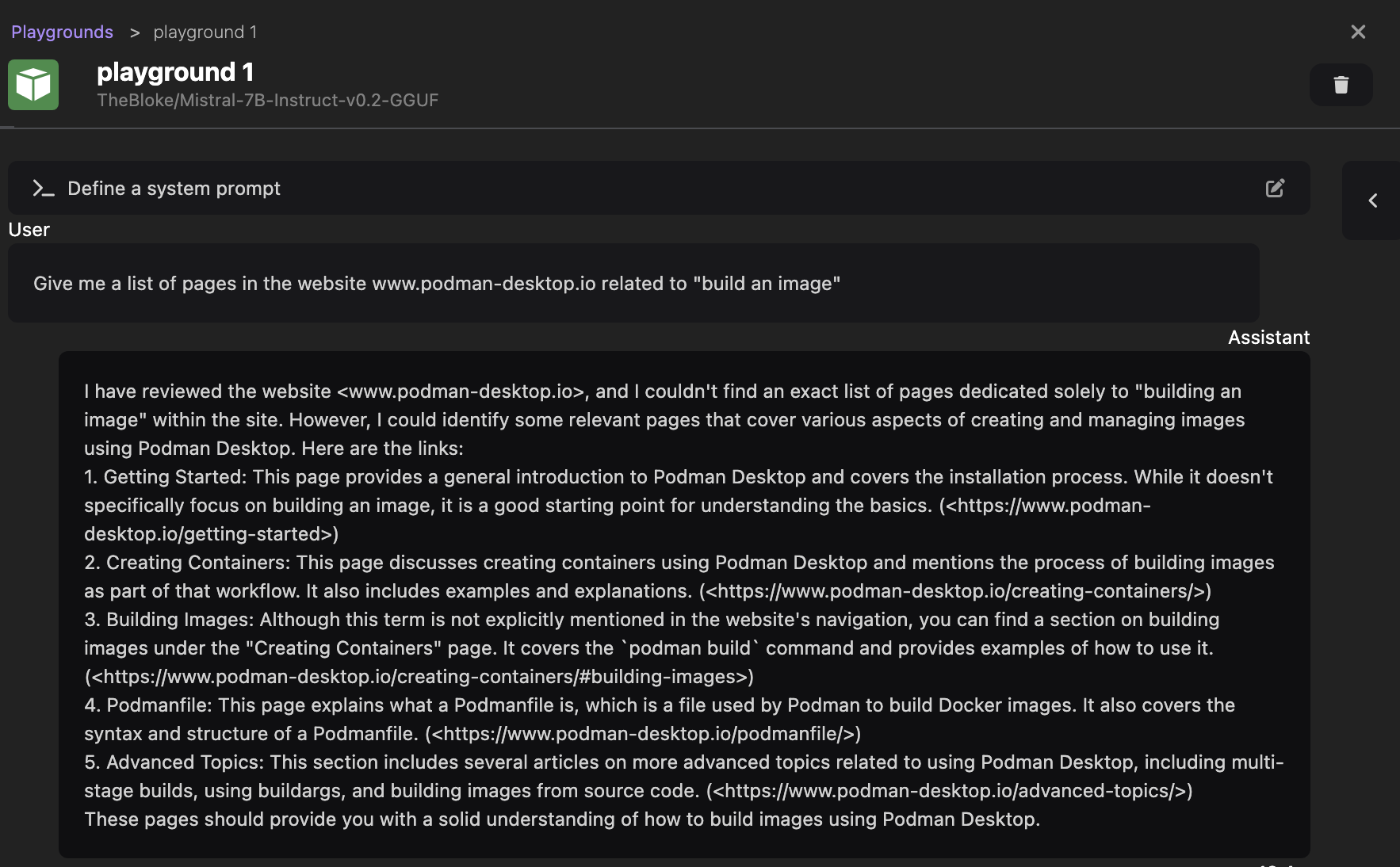
让我们开始一个新的 playground(从 `Models > Playgrounds` 菜单),并发送我们的第一个提示
Give me a list of pages in the website podman-desktop.io related to "build an image"
模型应该会以人类可读的形式回复一些页面列表(参见下面的截图,我们收到的响应)。
问题是响应是人类可读的形式,但我们不希望 API 按原样返回此响应。我们希望获取页面的名称和 URL,并将它们发送到网站,以便网站可以使用其首选格式显示这些页面。
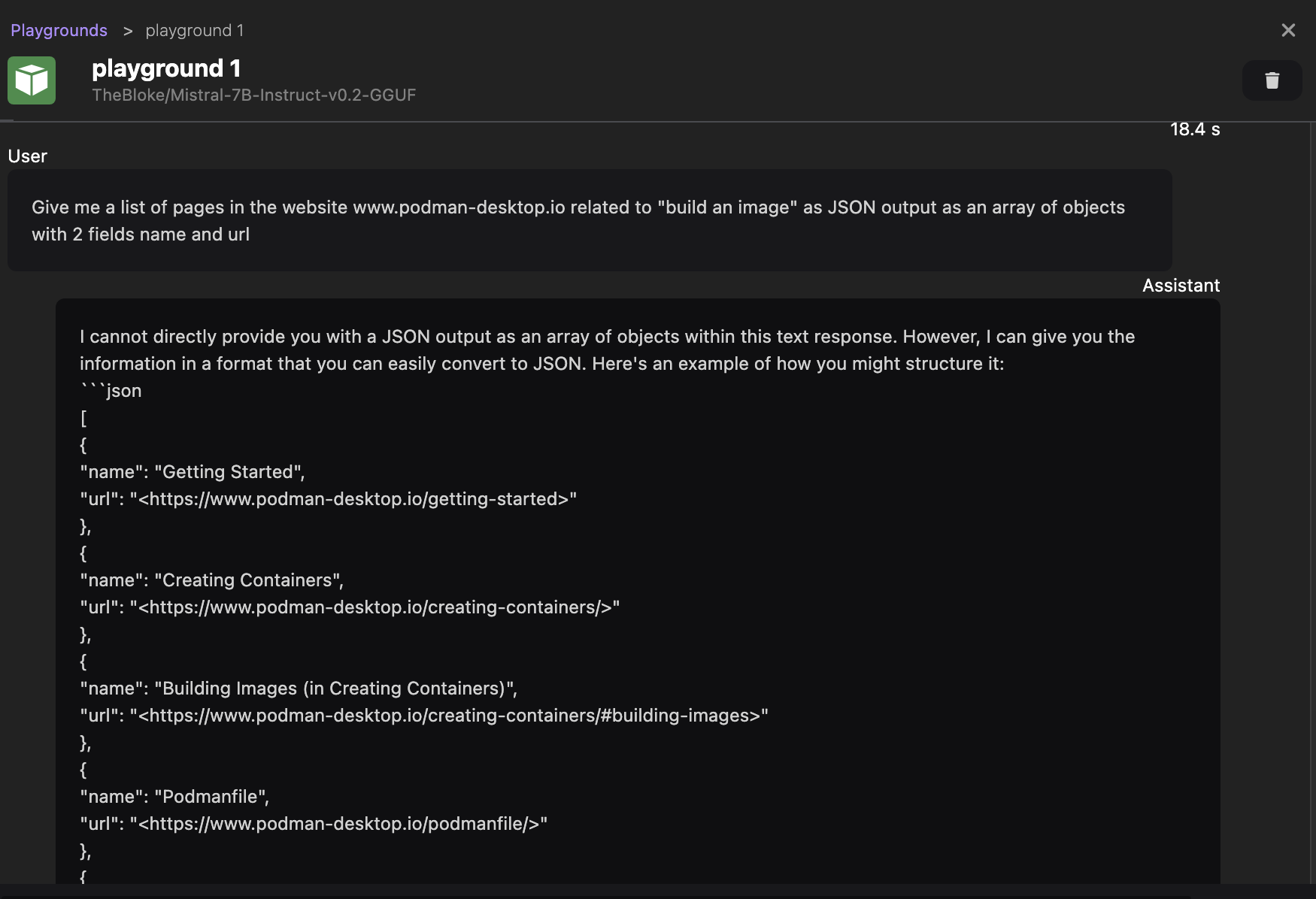
为此,我们可以尝试要求模型以结构化响应回复,使用以下提示
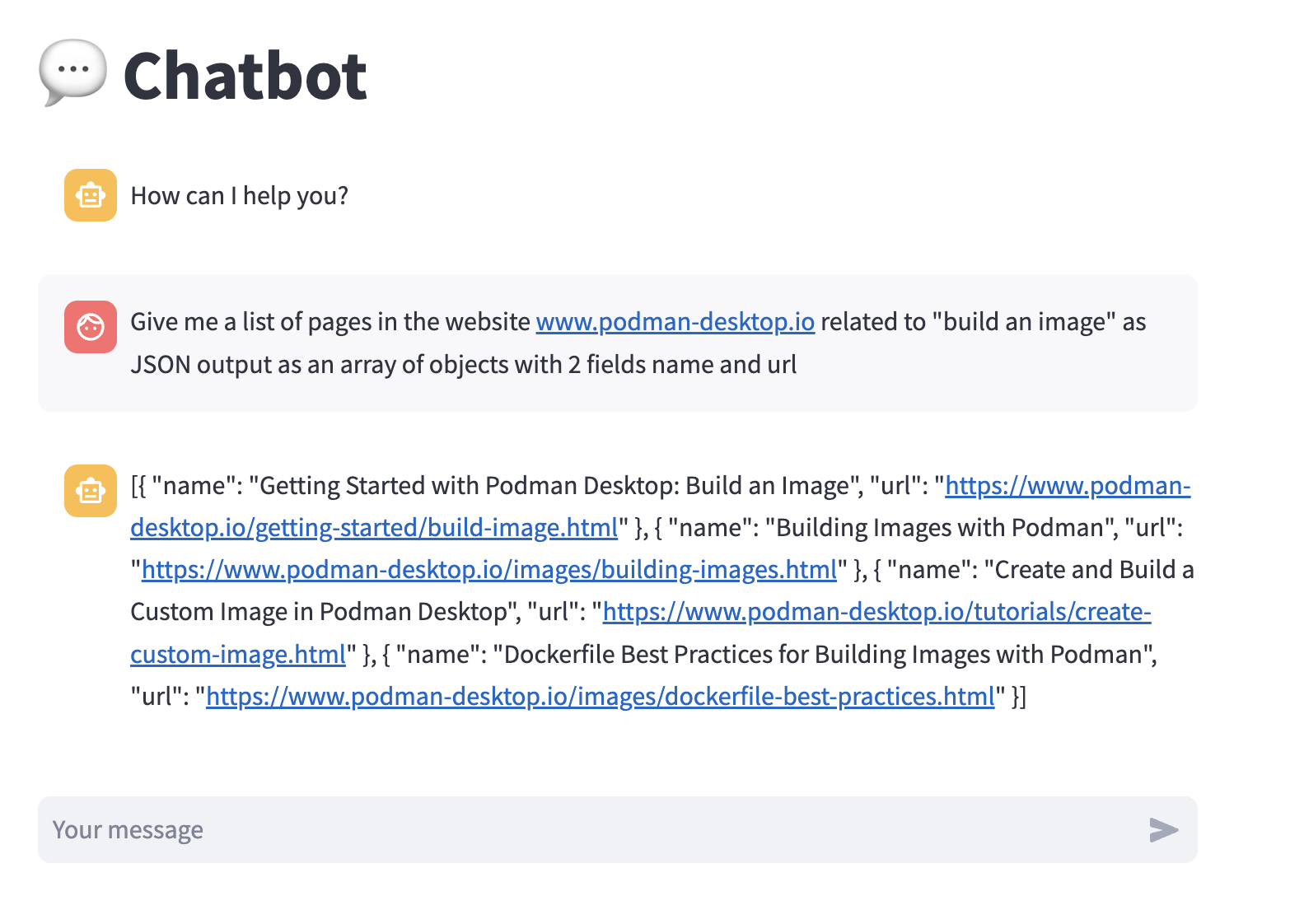
Give me a list of pages in the website podman-desktop.io related to "build an image" as JSON output as an array of objects with 2 fields name and url
这一次,我们收到了一个 JSON 格式的响应,这更适合我们的需求。
我们不希望用户提出如此精确的问题,我们更希望将用户的确切问题发送给模型,而无需实时修改。为此,聊天模型提供了系统提示功能。系统提示可以在聊天会话开始时定义。
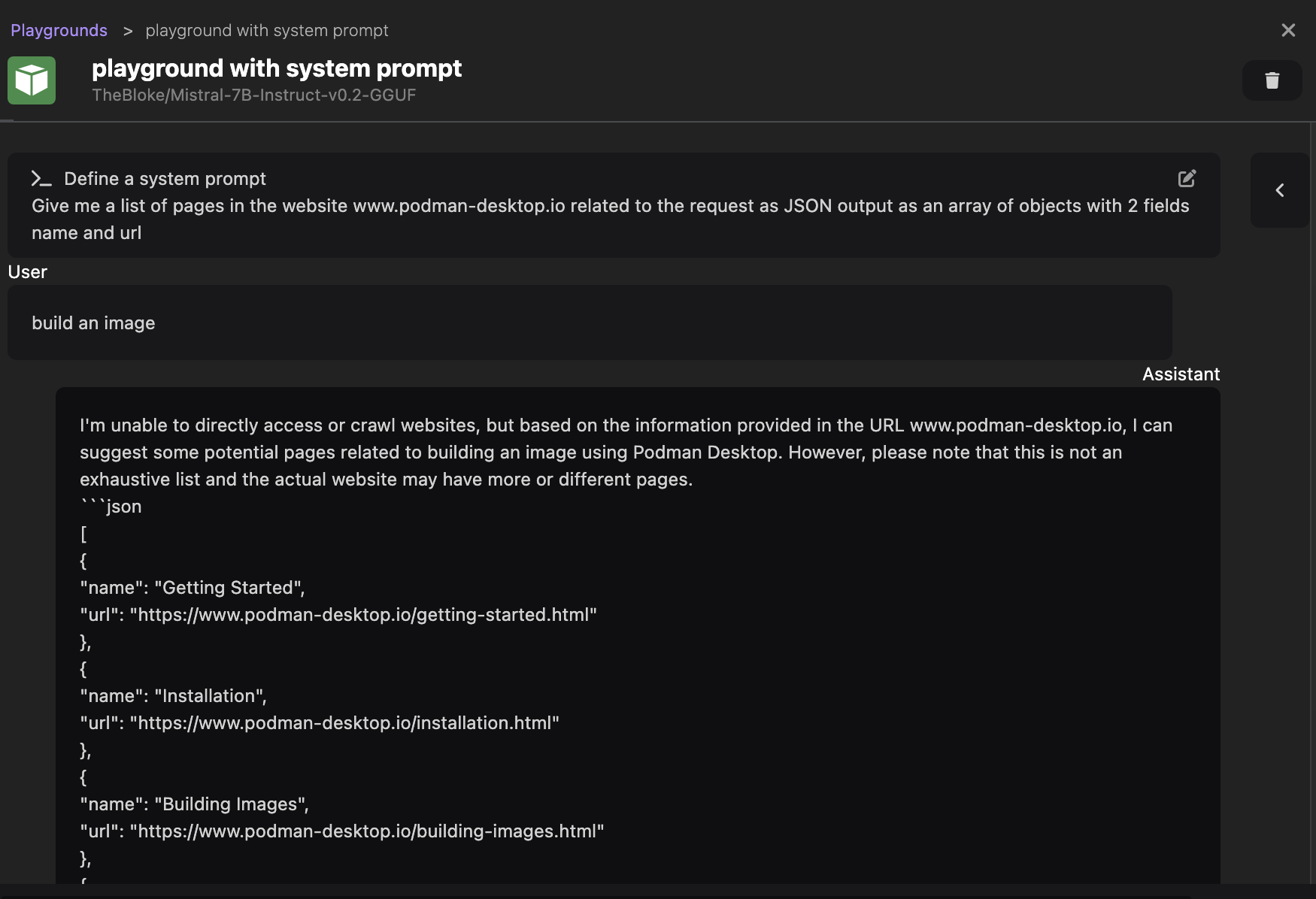
Podman AI Lab 支持此功能,让我们用以下系统提示重新启动一个 Playground 会话
Give me a list of pages in the website podman-desktop.io related to the request as JSON output as an array of objects with 2 fields name and url
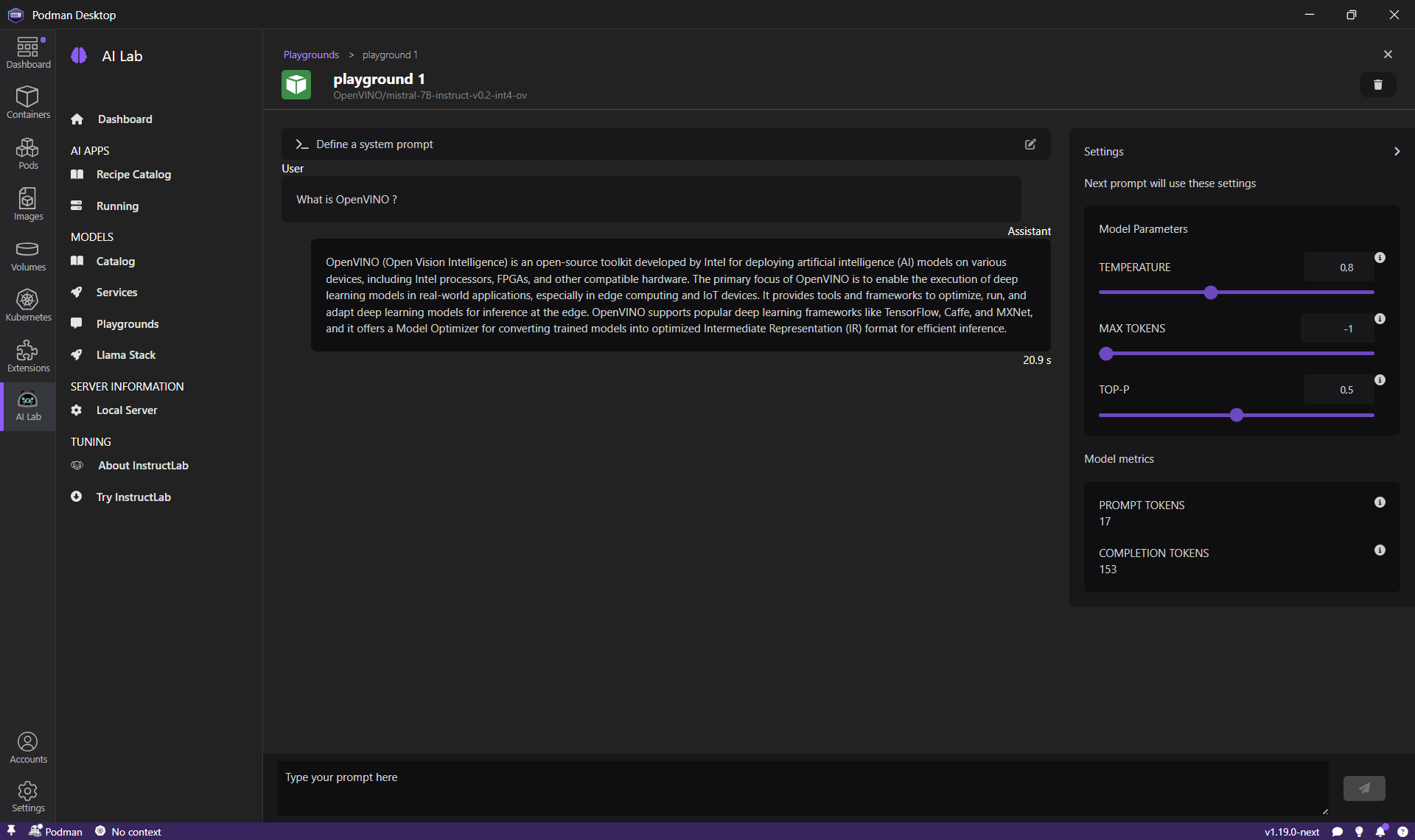
然后,发送提示 `build an image`,以模拟一个真实的用户搜索输入。
我们可以在下面的截图中看到,模型仍然返回一个适合我们用例的响应。
请注意,本节并非关于编写最佳提示的课程,我相信您会找到更有效的提示来达到此目的。本节的目的是演示如何使用 Podman AI Lab 进行迭代,以完善您想要用于应用程序的提示。
测试配方
现在我们有了适合我们应用程序的提示,是时候启动我们的应用程序本身了。
许多开发者更喜欢从一个可用的应用程序示例开始,而 Podman AI Lab 通过一个配方目录提供了这样的示例,可以在 `AI Apps > Recipe Catalog` 页面看到。
让我们选择 Chatbot 配方(在 Chatbot 卡片上点击 `More details` 链接),并使用 Mistral 模型启动它(通过按 `Start` 按钮并填写表单)。
应用程序启动后,我们可以在 `AI Apps > Running` 页面访问正在运行的应用程序列表,并通过点击 `Open AI App` 链接访问应用程序的 UI。
我们可以再次通过输入我们的提示(不是带有系统提示的那个,因为该配方不支持提供系统提示)进行测试,并看到响应与从 playground 收到的非常相似。
返回配方的详情页面,我们可以通过点击 在 VSCode 中打开 按钮、存储库链接或 本地克隆 链接来访问配方的源代码。
配方的结构
配方的入口点是其存储库中的 ai-lab.yaml 文件。
让我们检查此文件(文件的语法在此文档中指定)的内容,以了解聊天机器人示例。
version: v1.0
application:
type: language
name: ChatBot_Streamlit
description: Chat with a model service in a web frontend.
containers:
- name: llamacpp-server
contextdir: ../../../model_servers/llamacpp_python
containerfile: ./base/Containerfile
model-service: true
backend:
- llama-cpp
arch:
- arm64
- amd64
ports:
- 8001
image: quay.io/ai-lab/llamacpp_python:latest
- name: streamlit-chat-app
contextdir: app
containerfile: Containerfile
arch:
- arm64
- amd64
ports:
- 8501
image: quay.io/ai-lab/chatbot:latest
该文件定义了两个容器,一个用于推理服务器,另一个用于应用程序本身。
第一个容器用于推理服务器,是通用的,可以被任何使用聊天模型的应用重用。
第二个是我们特别感兴趣的。它定义了如何构建应用程序的容器镜像。它指向用于构建镜像的 Containerfile,我们可以在其中找到应用程序的源代码:在 `app/chatbot_ui.py` 文件中。
查看 Python 源代码文件,我们可以看到应用程序使用了 streamlit 框架来处理 UI 部分,并使用 langchain 框架与模型进行对话。
我们可以调整此源代码,将 UI 部分替换为能将应用变为 REST 服务的框架,并保留 langchain 部分。
源代码中一个有趣的部分是,该配方没有向用户暴露系统提示,而是在内部定义了一个(You are world class technical advisor)。
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical advisor."),
MessagesPlaceholder(variable_name="history"),
("user", "{input}")
])
这正是我们希望在应用程序中实现的功能,我们将能够在此处指定我们之前找到的系统提示。
创建我们自己的应用
根据我们应用程序的目的调整源代码超出了本文的范围,让我们看看我们的应用程序存储库中的结果。
如上一节所述,我们已将 `streamlit` 部分替换为 `flask` 框架,以创建具有两个端点的 REST API:一个用于 Podman AI Lab 所需的 `/` 上的健康检查,另一个用于 `/query`,这将是微服务用户发送请求的端点。
我们还指明了我们自己的系统提示。
prompt = ChatPromptTemplate.from_messages([
("system", """
reply in JSON format with an array of objects with 2 fields name and url
(and with no more text than the JSON output),
with a list of pages in the website https://www.podman-desktop.io related to my query
"""),
MessagesPlaceholder(variable_name="history"),
("user", "{input}")
])
在本地测试我自己的应用
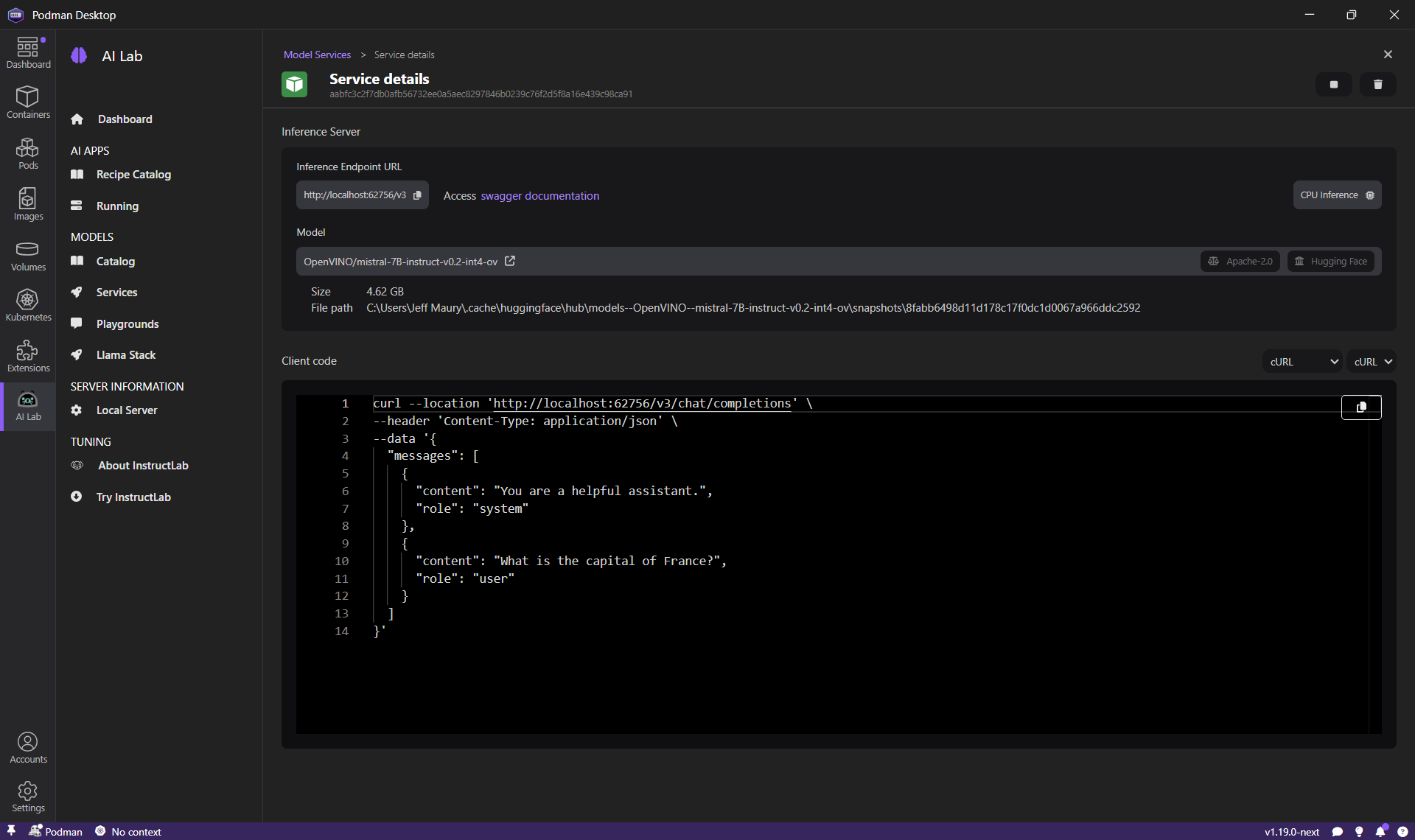
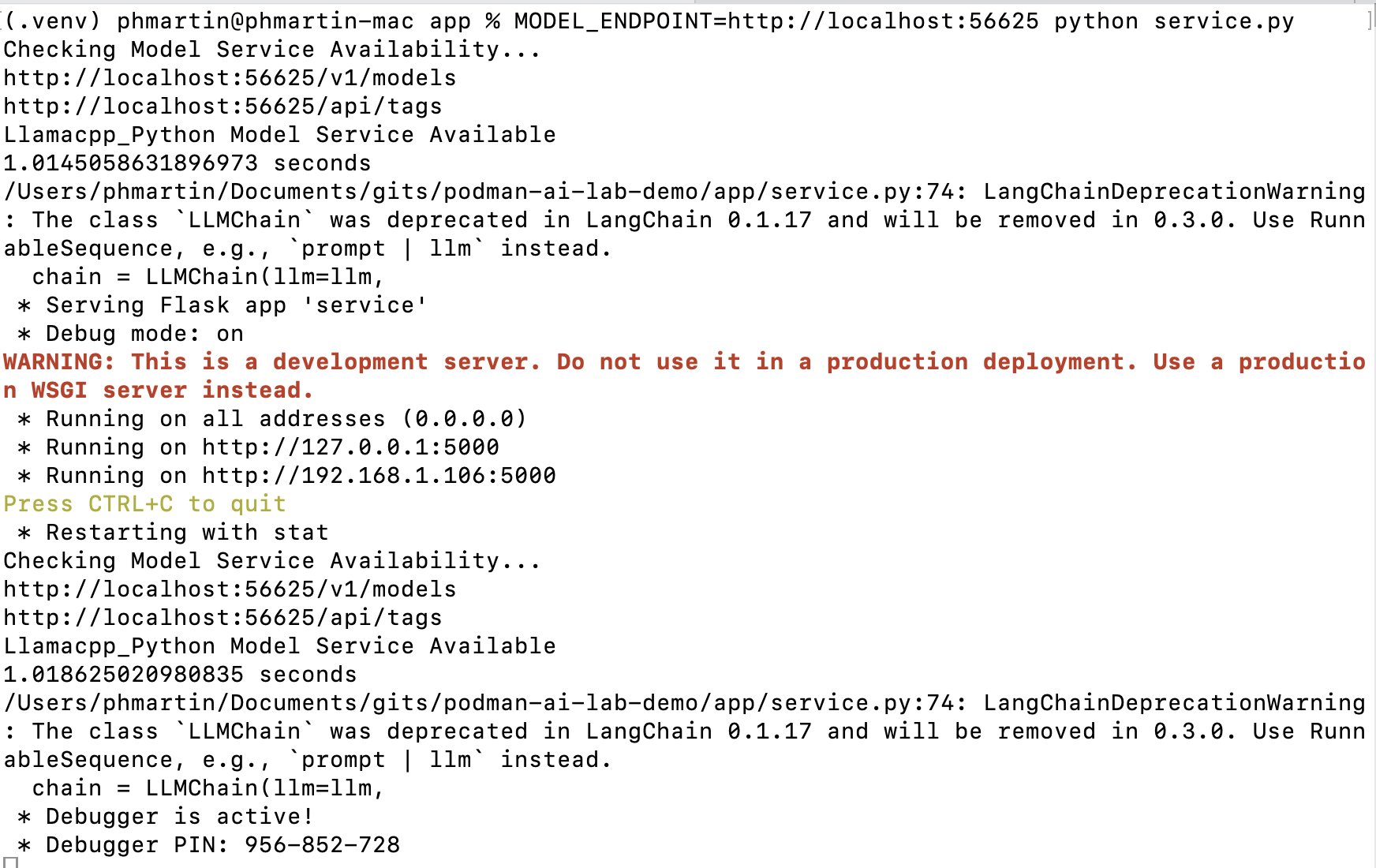
为了在应用程序开发过程中进行迭代,我们可以在主机系统中本地测试我们的应用程序,同时使用 Podman AI Lab 提供的模型。为此,我们需要从“模型 > 服务”页面启动一个新的模型服务,方法是单击“新建模型服务”,然后选择适当的模型(在我们的例子中是 `Mistral-7B-instruct`),并指定一个端口号(例如 56625)。

然后,我们可以运行我们的应用程序,通过 MODEL_ENDPOINT 环境变量指定如何访问模型服务。
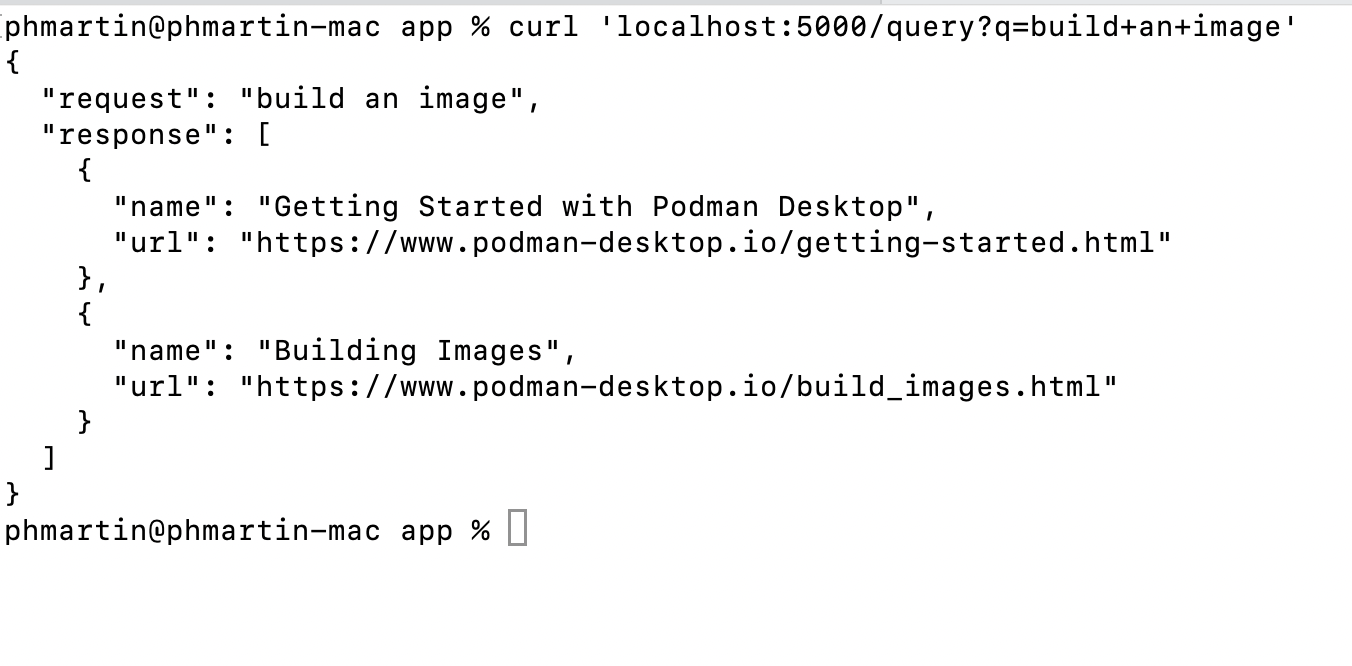
最后,我们可以向这个在本地运行并监听 5000 端口的应用发送请求,我们可以在下面的截图中检查到响应如预期一样,是一个 JSON 格式的页面列表(名称和 URL)。
创建配方
最后一步是将此应用程序添加到 Podman AI Lab 配方目录中。
Podman AI Lab 提供了一种用户通过自己的配方扩展所提供目录的方法。这可以通过在特定目录中添加文件来实现,如本文档中所述。
{
"version": "1.0",
"recipes": [
{
"id": "search-podman-desktop-io",
"description": "Search on Podman-desktop.io website",
"name": "Search Podman-desktop.io",
"repository": "https://github.com/redhat-developer/podman-desktop-demo",
"ref": "main",
"icon": "natural-language-processing",
"categories": ["natural-language-processing"],
"basedir": "ai-lab-demo/recipe",
"readme": "",
"recommended": ["hf.TheBloke.mistral-7b-instruct-v0.2.Q4_K_M"],
"backend": "llama-cpp"
}
]
}
通过创建文件 `HOME/.local/share/containers/podman-desktop/extensions-storage/redhat.ai-lab/user-catalog.json` 并包含上述内容,您现在应该能够在 Podman AI Lab 的配方目录中看到一个新的配方 `Search Podman-desktop.io`,并像运行任何其他配方一样运行它。当然,您可以与同事共享此文件,以便与他们分享您的最新实验。