为模型启动推理服务器
模型下载后,即可启动模型服务。模型服务是一个在容器中运行的推理服务器,它通过许多提供商通用的知名聊天 API 来暴露模型。
先决条件
步骤
-
在左侧导航窗格中单击 Podman AI Lab 图标。
-
在 Podman AI Lab 导航栏中,点击 Services(服务)。
-
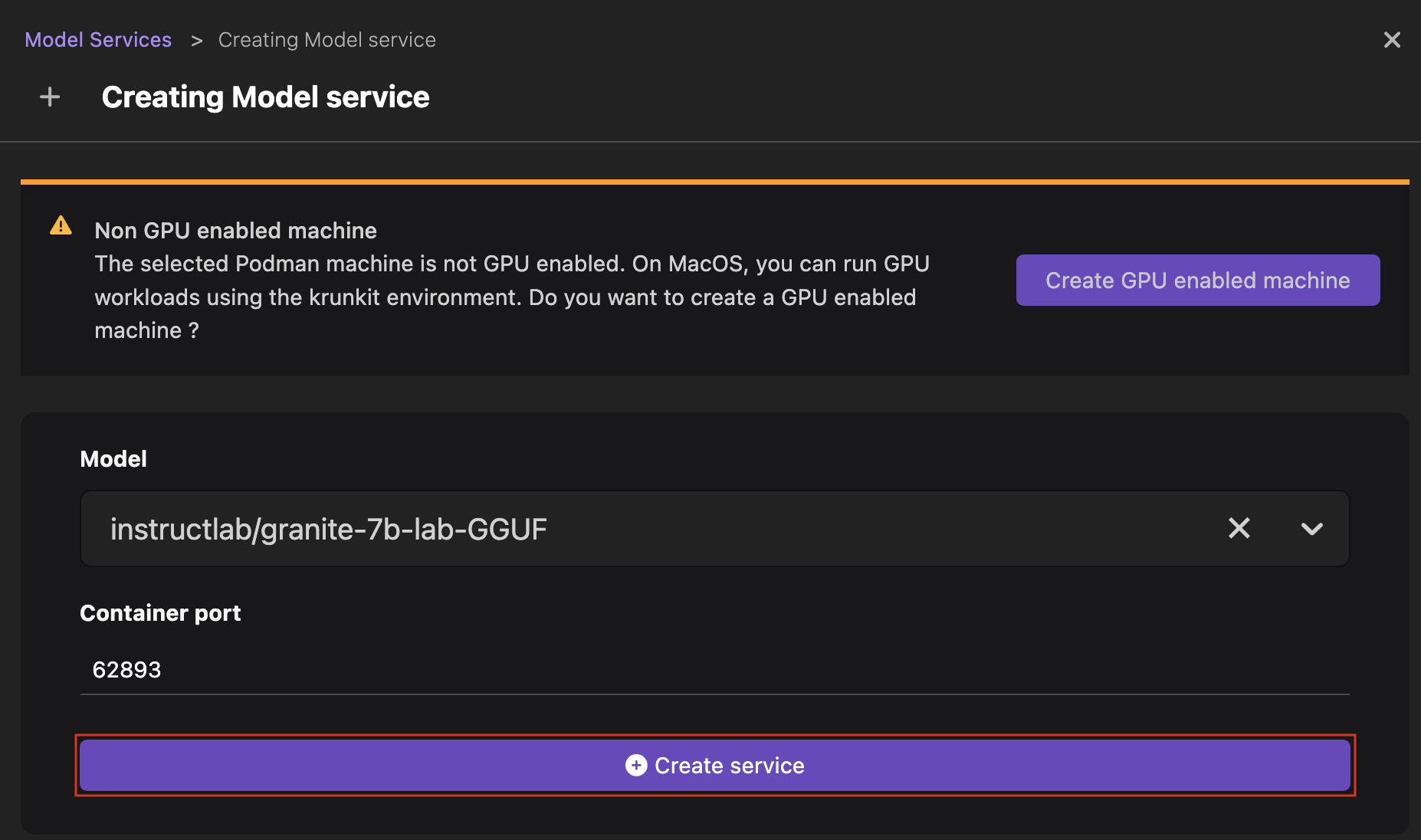
点击页面右上角的 New Model Service(新建模型服务)按钮。此时将打开创建模型服务页面。
注意在 macOS 机器上,您会收到一条通知,提示您创建一个支持 GPU 的 Podman machine 以运行您的 GPU 工作负载。点击 Create GPU enabled machine(创建支持 GPU 的 machine)按钮继续。
-
从下拉列表中选择您想要启动推理服务器的模型,并根据需要编辑端口号。
-
点击 Create service(创建服务)。该模型的推理服务器正在启动,这需要一些时间。
-
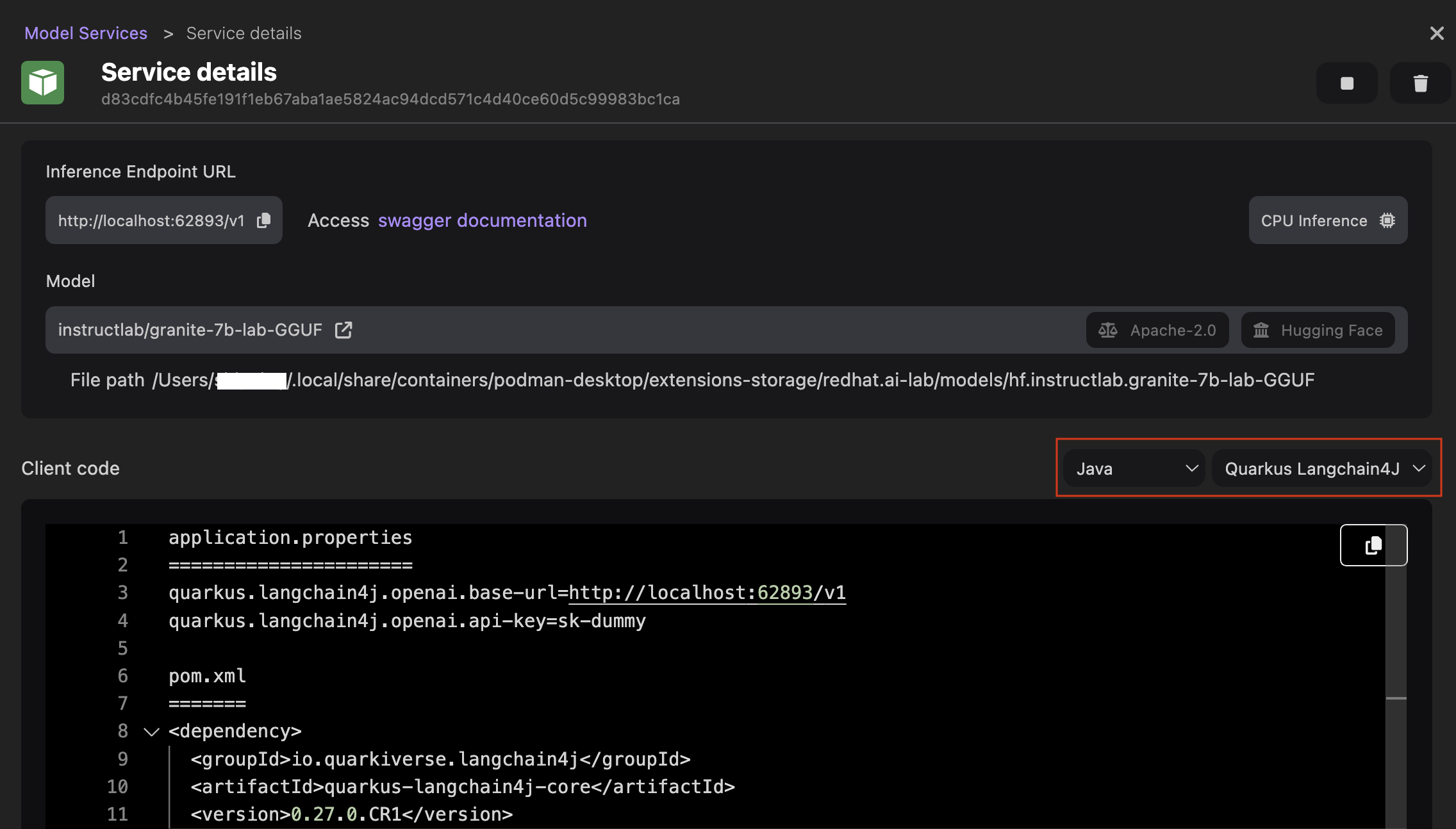
点击 Open service details(打开服务详情)按钮。
验证
- 查看推理服务器的详细信息。
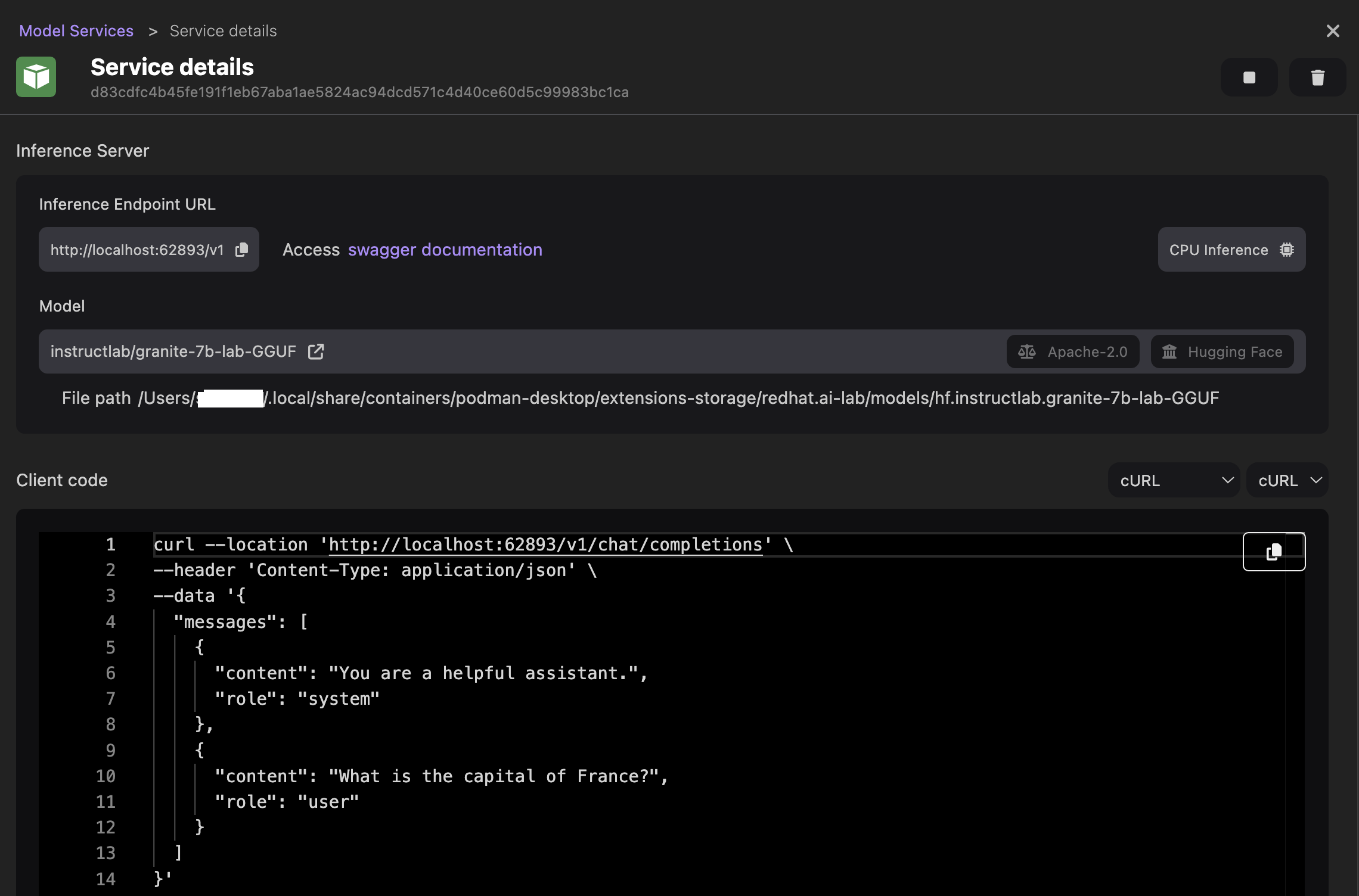
- 可选:根据您的编程语言自定义客户端代码,以通过推理服务器访问模型。例如,将代码语言设置为
Java和Quarkus Langchain4J,并查看更新后的代码片段。